大名顶顶的中文分词器 https://code.google.com/archive/p/ik-analyzer/ ,今天这里我们主要不是用在elastic search上,而是用于基础的分词,
IKSegmenter : 这是 IK 分词器的核心类。它是独立于 Lucene 的 Java 分词器实现。当您需要 在 Lucene 以外的环境中单独使用 IK 中文分词 组件时,IKSegmenter 正是您要找的。
主要是我今天写的代码里,JProfiler 里排名第一的卡CPU就是它,我生成两百万数据的话,足足卡了我10分钟!!
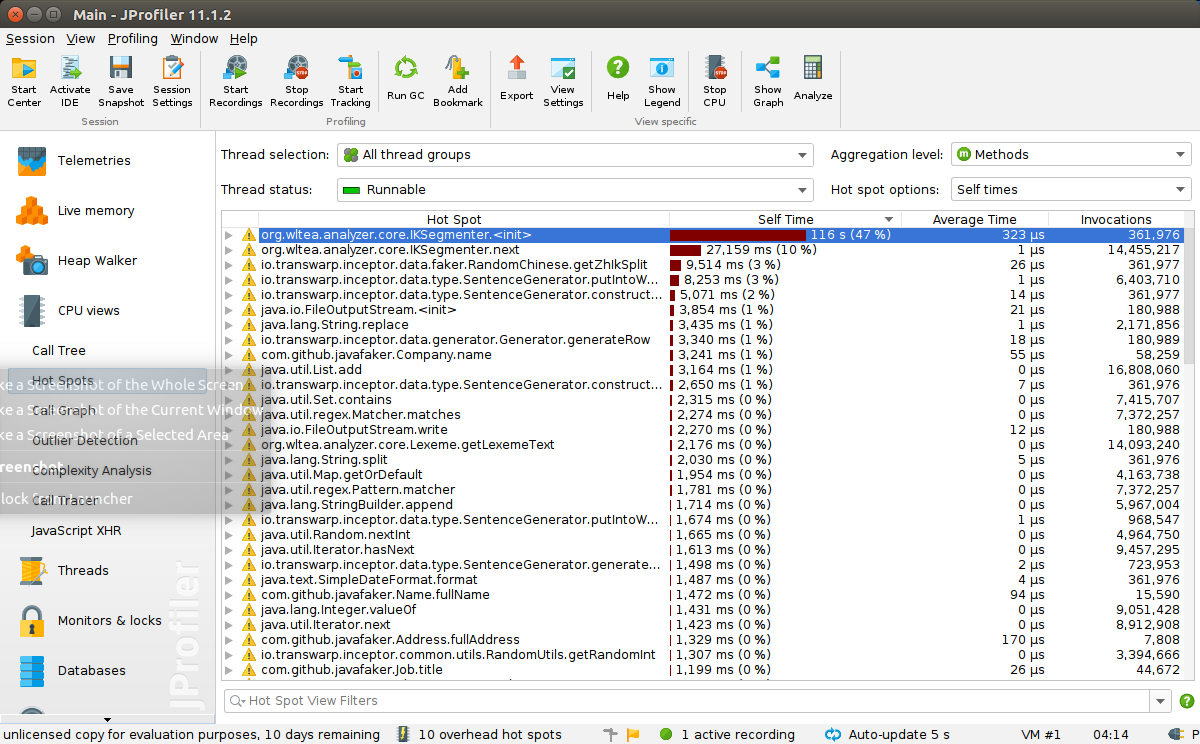
原因在于,我参考标准写法每次都新生成一个IKSegmenter对象,
下面是两个构造函数:
/**
* IK主分词器构造函数
* 默认最细粒度切分
* @param input
*/
public IKSegmentation(Reader input){
this(input , false);
}
/**
* IK主分词器构造函数
* @param input
* @param isMaxWordLength 当为true时,分词器进行最大词长切分
*/
public IKSegmentation(Reader input , boolean isMaxWordLength){
this.input = input ;
segmentBuff = new char[BUFF_SIZE];
context = new Context(segmentBuff , isMaxWordLength);
segmenters = Configuration.loadSegmenter();
}
我们可以看到每个构造函数都必须传入input进去,
我就简单的写了
String sentence = "这是一句话";
IKSegmentation iKSegmentation = new IKSegmentation(new StringReader(sentence), true);
然后包装成一个方法,每次传入一句话进去,这就导致了开篇的图中它吃掉了最多的CPU时间,
网上搜寻了很久无果,我想着我要把这个东西挪出去,不能每次都生成,最好复用一下,
一开始想的是我换一个Reader比如说什么InputstreamReader,但是发现并不可以,它都input是在构造的时候指定了就赋值好了,那么,仔细研究一下这个类,发现input还有一次被重新赋值的机会,就是reset函数
/**
* 重置分词器到初始状态
* @param input
*/
public synchronized void reset(Reader input) {
this.input = input;
context.resetContext();
for(ISegmenter segmenter : segmenters){
segmenter.reset();
}
}
可以看到源码里面调用reset的时候是可以新输入一个reader的,这就解决了大问题!
我们把IKSegmentation定义在外面,注意这里有个小技巧(传入一个空字符串"")初始化,然后调用函数时,重新生成一个StringReader并reset,这样我们就把排名第一的生成多个对象的问题给解决了!
IKSegmentation iKSegmentation = new IKSegmentation(new StringReader(""), true);
public List<String> getIkWords(String sentence){
iKSegmentation.reset(new StringReader(sentence));
//.......
}
什么,你要问排名第二的next咋办,这个源码里只有next方法能用,还能咋办,哈哈哈